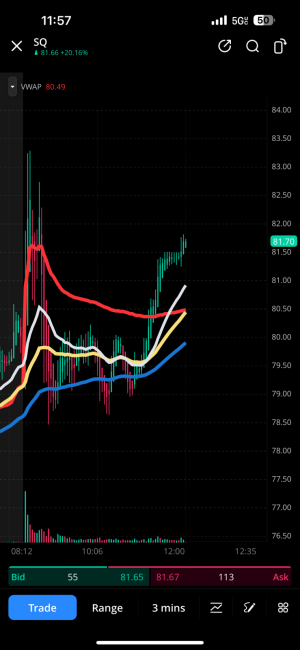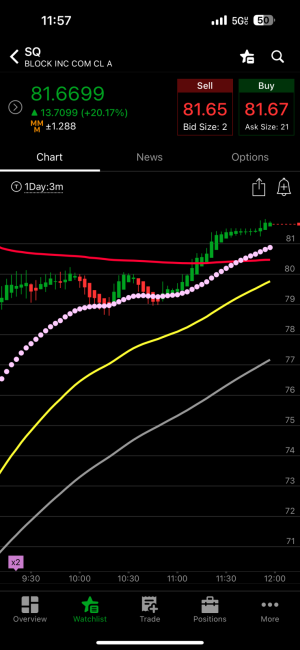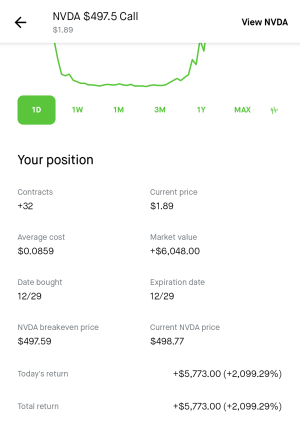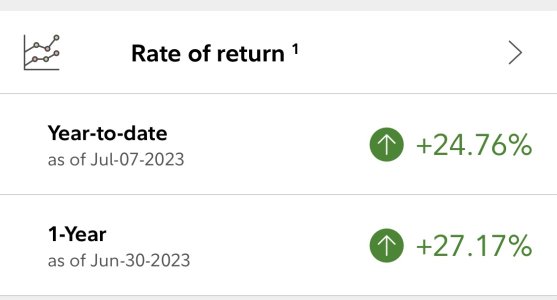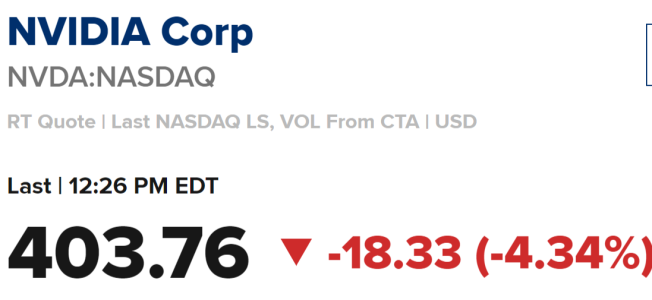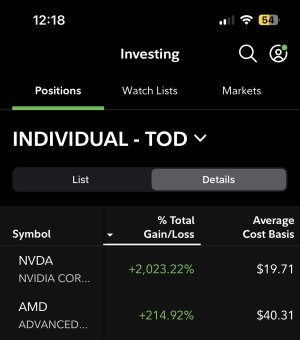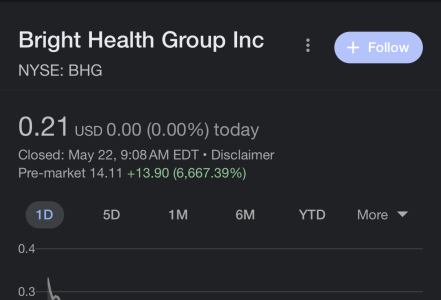
- 4,590
- 6,874
- Joined
- Jan 14, 2014
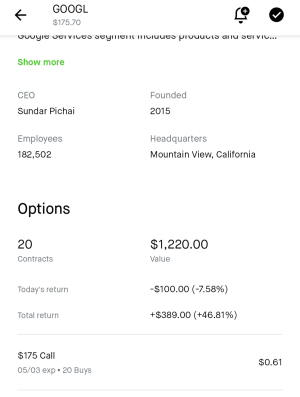
Anyone in or heard of Paysafe? Ran across them and saw that they were teaming up with Coinbase, which caught my attention.

Looked at their ratings and numbers, and since their price was so low I took the jump. If anyone else has any other insight on how they look please share.
Paysafe’s Skrill Expands Crypto Offering to US With Coinbase
Paysafe, a leading specialized payments platform, today announced that its Skrill digital wallet has expanded its cryptocurrency offering to the U.S.
www.businesswire.com
Looked at their ratings and numbers, and since their price was so low I took the jump. If anyone else has any other insight on how they look please share.






 AI Progress Depends on Semiconductors
AI Progress Depends on Semiconductors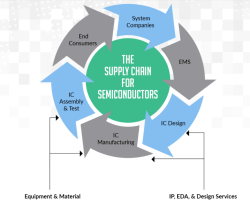 Semiconductor Supply Chain (Source: TSMC)
Semiconductor Supply Chain (Source: TSMC)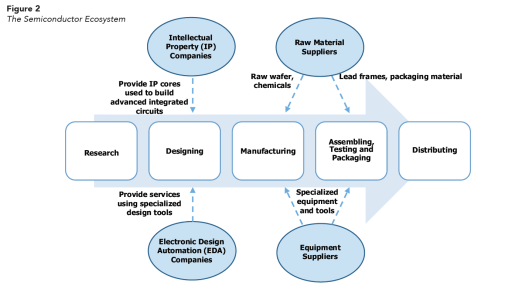 Supply Chain Overview – SIA
Supply Chain Overview – SIA
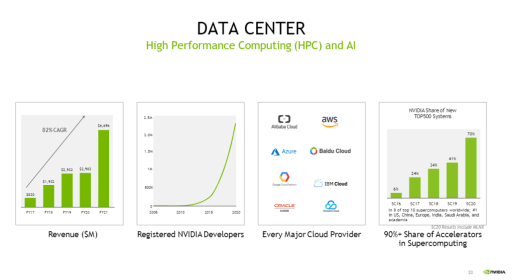 NVDA Data Center Business – Source: NVDA Investor Presentation
NVDA Data Center Business – Source: NVDA Investor Presentation AI TAM – Source: NVDA Investor Presentation
AI TAM – Source: NVDA Investor Presentation
 Widespread Usage of TensorFlow
Widespread Usage of TensorFlow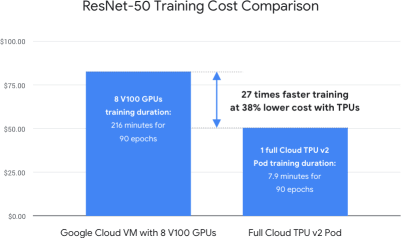 TPU v3 Pod with Better Performance
TPU v3 Pod with Better Performance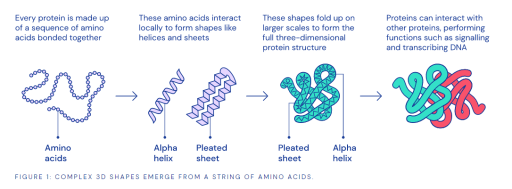 Why Protein Folding is So Complex
Why Protein Folding is So Complex



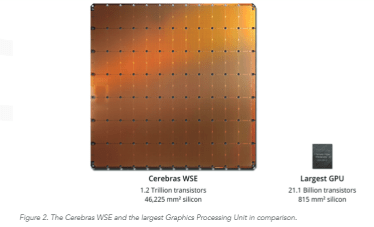 The Cerebras WSE is Massive
The Cerebras WSE is Massive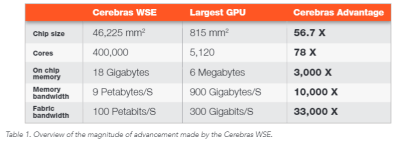 Cerebras WSE Comparison
Cerebras WSE Comparison